Description: Download the Spotify songs data set. Create a SQLite3 schema to store this data in at least 3rd normal form (3NF), and populate the tables. Use an SQL query to find the names of all playlists that contain instrumentals.
Spotify Songs Dataset
First, let’s download and see the dataset we gonna use. It is a dataset of Spotify songs.
df = pd.read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-01-21/spotify_songs.csv')`
df
| track_id | track_name | track_artist | track_popularity | track_album_id | track_album_name | track_album_release_date | playlist_name | playlist_id | playlist_genre | … | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | duration_ms | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | I Don’t Care (with Justin Bieber) - Loud Luxur… | Ed Sheeran | 66 | 2oCs0DGTsRO98Gh5ZSl2Cx | I Don’t Care (with Justin Bieber) [Loud Luxury… | 2019-06-14 | Pop Remix | 37i9dQZF1DXcZDD7cfEKhW | pop | … | 6 | -2.634 | 1 | 0.0583 | 0.102000 | 0.000000 | 0.0653 | 0.5180 | 122.036 | 194754 |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | Memories - Dillon Francis Remix | Maroon 5 | 67 | 63rPSO264uRjW1X5E6cWv6 | Memories (Dillon Francis Remix) | 2019-12-13 | Pop Remix | 37i9dQZF1DXcZDD7cfEKhW | pop | … | 11 | -4.969 | 1 | 0.0373 | 0.072400 | 0.004210 | 0.3570 | 0.6930 | 99.972 | 162600 |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | All the Time - Don Diablo Remix | Zara Larsson | 70 | 1HoSmj2eLcsrR0vE9gThr4 | All the Time (Don Diablo Remix) | 2019-07-05 | Pop Remix | 37i9dQZF1DXcZDD7cfEKhW | pop | … | 1 | -3.432 | 0 | 0.0742 | 0.079400 | 0.000023 | 0.1100 | 0.6130 | 124.008 | 176616 |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | Call You Mine - Keanu Silva Remix | The Chainsmokers | 60 | 1nqYsOef1yKKuGOVchbsk6 | Call You Mine - The Remixes | 2019-07-19 | Pop Remix | 37i9dQZF1DXcZDD7cfEKhW | pop | … | 7 | -3.778 | 1 | 0.1020 | 0.028700 | 0.000009 | 0.2040 | 0.2770 | 121.956 | 169093 |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | Someone You Loved - Future Humans Remix | Lewis Capaldi | 69 | 7m7vv9wlQ4i0LFuJiE2zsQ | Someone You Loved (Future Humans Remix) | 2019-03-05 | Pop Remix | 37i9dQZF1DXcZDD7cfEKhW | pop | … | 1 | -4.672 | 1 | 0.0359 | 0.080300 | 0.000000 | 0.0833 | 0.7250 | 123.976 | 189052 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 32828 | 7bxnKAamR3snQ1VGLuVfC1 | City Of Lights - Official Radio Edit | Lush & Simon | 42 | 2azRoBBWEEEYhqV6sb7JrT | City Of Lights (Vocal Mix) | 2014-04-28 | ♥ EDM LOVE 2020 | 6jI1gFr6ANFtT8MmTvA2Ux | edm | … | 2 | -1.814 | 1 | 0.0936 | 0.076600 | 0.000000 | 0.0668 | 0.2100 | 128.170 | 204375 |
| 32829 | 5Aevni09Em4575077nkWHz | Closer - Sultan & Ned Shepard Remix | Tegan and Sara | 20 | 6kD6KLxj7s8eCE3ABvAyf5 | Closer Remixed | 2013-03-08 | ♥ EDM LOVE 2020 | 6jI1gFr6ANFtT8MmTvA2Ux | edm | … | 0 | -4.462 | 1 | 0.0420 | 0.001710 | 0.004270 | 0.3750 | 0.4000 | 128.041 | 353120 |
| 32830 | 7ImMqPP3Q1yfUHvsdn7wEo | Sweet Surrender - Radio Edit | Starkillers | 14 | 0ltWNSY9JgxoIZO4VzuCa6 | Sweet Surrender (Radio Edit) | 2014-04-21 | ♥ EDM LOVE 2020 | 6jI1gFr6ANFtT8MmTvA2Ux | edm | … | 6 | -4.899 | 0 | 0.0481 | 0.108000 | 0.000001 | 0.1500 | 0.4360 | 127.989 | 210112 |
| 32831 | 2m69mhnfQ1Oq6lGtXuYhgX | Only For You - Maor Levi Remix | Mat Zo | 15 | 1fGrOkHnHJcStl14zNx8Jy | Only For You (Remixes) | 2014-01-01 | ♥ EDM LOVE 2020 | 6jI1gFr6ANFtT8MmTvA2Ux | edm | … | 2 | -3.361 | 1 | 0.1090 | 0.007920 | 0.127000 | 0.3430 | 0.3080 | 128.008 | 367432 |
| 32832 | 29zWqhca3zt5NsckZqDf6c | Typhoon - Original Mix | Julian Calor | 27 | 0X3mUOm6MhxR7PzxG95rAo | Typhoon/Storm | 2014-03-03 | ♥ EDM LOVE 2020 | 6jI1gFr6ANFtT8MmTvA2Ux | edm | … | 5 | -4.571 | 0 | 0.0385 | 0.000133 | 0.341000 | 0.7420 | 0.0894 | 127.984 | 337500 |
32833 rows × 23 columns
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32833 entries, 0 to 32832
Data columns (total 23 columns):
track_id 32833 non-null object
track_name 32828 non-null object
track_artist 32828 non-null object
track_popularity 32833 non-null int64
track_album_id 32833 non-null object
track_album_name 32828 non-null object
track_album_release_date 32833 non-null object
playlist_name 32833 non-null object
playlist_id 32833 non-null object
playlist_genre 32833 non-null object
playlist_subgenre 32833 non-null object
danceability 32833 non-null float64
energy 32833 non-null float64
key 32833 non-null int64
loudness 32833 non-null float64
mode 32833 non-null int64
speechiness 32833 non-null float64
acousticness 32833 non-null float64
instrumentalness 32833 non-null float64
liveness 32833 non-null float64
valence 32833 non-null float64
tempo 32833 non-null float64
duration_ms 32833 non-null int64
dtypes: float64(9), int64(4), object(10)
memory usage: 5.8+ MB
Database normalization Concepts
Now, let’s quick go through some concepts about database normalization.
Database normalization is performed for two main reasons - reduce redundancy and prevent inconsistencies on insert/update/delete.
Note: A fully normalized database is in domain-key normal form (DK/NF) if every constraint is a logical consequence of the definition of the candidate key and domains. However, most practical normalization procedures go through a series of steps known as first, second and third normal forms, and ignore potential modification anomalies that may remain.
First Normal Form (1NF)
- Table has a primary key (unique, non-null column that identifies each row)
- No repeating groups of columns
- Each cell contains a single value
Second Normal Form (2NF)
All columns in each row depend fully on candidate keys. This can be quite tricky to understand.
- Look for candidate composite keys that can uniquely identify a row.
- See if the other columns depend on ALL columns of the composite key.
In the sample example below, suppose we have a table for academic books. Note that (publisher, title) is a candidate key. However, headquarters depends only on publisher and not on title, so this violates 2NF.
| publisher | headquarter | title | |
|---|---|---|---|
| 0 | Springer | Germany | Linear Algebra Done Wrong |
| 1 | Springer | Gernamy | Undergraduate Algebra |
| 2 | CUB | England | Stochastic Modelling of Reaction–Diffusion Pro… |
| 3 | CUP | England | An Introduction to Stochastic Dynamics |
Third Normal Form (3NF)
No transitive dependencies between non-candidate columns. In the table below, both major and major_description depend on the name (or row number), but major_description only depends on name via the major. This is a transitive dependency and violates 3NF.
| name | age | major | major_dscription | |
|---|---|---|---|---|
| 0 | ann | 21 | math | Mathematics |
| 1 | bob | 22 | stats | Statisitcs |
| 2 | charles | 21 | bio | Biohazards in the University |
| 3 | david | 23 | math | Mathematics |
Normalizing the Spotify dataset
Is our Spotify dataset normalized? Yes, but only in first normal form (1NF). It is obvious that there are no repeating columns in the dataset and each column contains only single value. For converting the dataset into third normal form, we need to have a closer look at each columns.
for col in df.columns:
print(col)
track_id
track_name
track_artist
track_popularity
track_album_id
track_album_name
track_album_release_date
playlist_name
playlist_id
playlist_genre
playlist_subgenre
danceability
energy
key
loudness
mode
speechiness
acousticness
instrumentalness
liveness
valence
tempo
duration_ms
Besed on these columns, we can break the dataset into three parts:
-
Track
-
Album
-
Playlist
track_id, track_name, track_artist, track_popularity. These are columns that should be in the track table. In addition, variables such as danceability are features of the track, even though they don’t start with “track”. This is the case for all columns following danceability, including energy, key, and all the way up to duration_ms.
Finally, we need to check the conditions for the dataset to be in the third normal form. Take track_name, for instance. Knowing track_name allows me to identify other characteristics of the track without having to know its primary key - track_id, which is kind of transitive dependencies. Therefor, we have to take track_name out of the table and store it in a table of its own.
df_track = pd.concat([df.iloc[:,[0,2,3]],df.iloc[:,11:]],axis=1).drop_duplicates()
df_track
| track_id | track_artist | track_popularity | danceability | energy | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | duration_ms | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | Ed Sheeran | 66 | 0.748 | 0.916 | 6 | -2.634 | 1 | 0.0583 | 0.102000 | 0.000000 | 0.0653 | 0.5180 | 122.036 | 194754 |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | Maroon 5 | 67 | 0.726 | 0.815 | 11 | -4.969 | 1 | 0.0373 | 0.072400 | 0.004210 | 0.3570 | 0.6930 | 99.972 | 162600 |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | Zara Larsson | 70 | 0.675 | 0.931 | 1 | -3.432 | 0 | 0.0742 | 0.079400 | 0.000023 | 0.1100 | 0.6130 | 124.008 | 176616 |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | The Chainsmokers | 60 | 0.718 | 0.930 | 7 | -3.778 | 1 | 0.1020 | 0.028700 | 0.000009 | 0.2040 | 0.2770 | 121.956 | 169093 |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | Lewis Capaldi | 69 | 0.650 | 0.833 | 1 | -4.672 | 1 | 0.0359 | 0.080300 | 0.000000 | 0.0833 | 0.7250 | 123.976 | 189052 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 32828 | 7bxnKAamR3snQ1VGLuVfC1 | Lush & Simon | 42 | 0.428 | 0.922 | 2 | -1.814 | 1 | 0.0936 | 0.076600 | 0.000000 | 0.0668 | 0.2100 | 128.170 | 204375 |
| 32829 | 5Aevni09Em4575077nkWHz | Tegan and Sara | 20 | 0.522 | 0.786 | 0 | -4.462 | 1 | 0.0420 | 0.001710 | 0.004270 | 0.3750 | 0.4000 | 128.041 | 353120 |
| 32830 | 7ImMqPP3Q1yfUHvsdn7wEo | Starkillers | 14 | 0.529 | 0.821 | 6 | -4.899 | 0 | 0.0481 | 0.108000 | 0.000001 | 0.1500 | 0.4360 | 127.989 | 210112 |
| 32831 | 2m69mhnfQ1Oq6lGtXuYhgX | Mat Zo | 15 | 0.626 | 0.888 | 2 | -3.361 | 1 | 0.1090 | 0.007920 | 0.127000 | 0.3430 | 0.3080 | 128.008 | 367432 |
| 32832 | 29zWqhca3zt5NsckZqDf6c | Julian Calor | 27 | 0.603 | 0.884 | 5 | -4.571 | 0 | 0.0385 | 0.000133 | 0.341000 | 0.7420 | 0.0894 | 127.984 | 337500 |
28356 rows × 15 columns
df_track_name = df.iloc[:,[0,1]].drop_duplicates()
df_track_name
| track_id | track_name | |
|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | I Don’t Care (with Justin Bieber) - Loud Luxur… |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | Memories - Dillon Francis Remix |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | All the Time - Don Diablo Remix |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | Call You Mine - Keanu Silva Remix |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | Someone You Loved - Future Humans Remix |
| … | … | … |
| 32828 | 7bxnKAamR3snQ1VGLuVfC1 | City Of Lights - Official Radio Edit |
| 32829 | 5Aevni09Em4575077nkWHz | Closer - Sultan & Ned Shepard Remix |
| 32830 | 7ImMqPP3Q1yfUHvsdn7wEo | Sweet Surrender - Radio Edit |
| 32831 | 2m69mhnfQ1Oq6lGtXuYhgX | Only For You - Maor Levi Remix |
| 32832 | 29zWqhca3zt5NsckZqDf6c | Typhoon - Original Mix |
28356 rows × 2 columns
There are three columns that are related to the Album attributes - track_album_id,track_album_name and track_album_release_date.
The third normal form constraint is also applied in this entity. While the id is the most natural primary key, note that if you know the album’s name, you may be able to identify its release date without knowing its id. So we’ll have to split these columns into different tables.
df_album_name = df.iloc[:,[4,5]].drop_duplicates()
df_album_name
| track_album_id | track_album_name | |
|---|---|---|
| 0 | 2oCs0DGTsRO98Gh5ZSl2Cx | I Don’t Care (with Justin Bieber) [Loud Luxury… |
| 1 | 63rPSO264uRjW1X5E6cWv6 | Memories (Dillon Francis Remix) |
| 2 | 1HoSmj2eLcsrR0vE9gThr4 | All the Time (Don Diablo Remix) |
| 3 | 1nqYsOef1yKKuGOVchbsk6 | Call You Mine - The Remixes |
| 4 | 7m7vv9wlQ4i0LFuJiE2zsQ | Someone You Loved (Future Humans Remix) |
| … | … | … |
| 32828 | 2azRoBBWEEEYhqV6sb7JrT | City Of Lights (Vocal Mix) |
| 32829 | 6kD6KLxj7s8eCE3ABvAyf5 | Closer Remixed |
| 32830 | 0ltWNSY9JgxoIZO4VzuCa6 | Sweet Surrender (Radio Edit) |
| 32831 | 1fGrOkHnHJcStl14zNx8Jy | Only For You (Remixes) |
| 32832 | 0X3mUOm6MhxR7PzxG95rAo | Typhoon/Storm |
22545 rows × 2 columns
df_album_release = df.loc[:,['track_album_id','track_album_release_date']].drop_duplicates()
df_album_release
| track_album_id | track_album_release_date | |
|---|---|---|
| 0 | 2oCs0DGTsRO98Gh5ZSl2Cx | 2019-06-14 |
| 1 | 63rPSO264uRjW1X5E6cWv6 | 2019-12-13 |
| 2 | 1HoSmj2eLcsrR0vE9gThr4 | 2019-07-05 |
| 3 | 1nqYsOef1yKKuGOVchbsk6 | 2019-07-19 |
| 4 | 7m7vv9wlQ4i0LFuJiE2zsQ | 2019-03-05 |
| … | … | … |
| 32828 | 2azRoBBWEEEYhqV6sb7JrT | 2014-04-28 |
| 32829 | 6kD6KLxj7s8eCE3ABvAyf5 | 2013-03-08 |
| 32830 | 0ltWNSY9JgxoIZO4VzuCa6 | 2014-04-21 |
| 32831 | 1fGrOkHnHJcStl14zNx8Jy | 2014-01-01 |
| 32832 | 0X3mUOm6MhxR7PzxG95rAo | 2014-03-03 |
22545 rows × 2 columns
There are four columns that are related to the Playlist - playlist_name, playlist_id, playlist_genre and playlist_subgenre.
Since if we know the name of the playlist, we may be able to guess its genre as well as its subgenere. So there exists some dependencies between these columns to some extent. In addition, we find that if we know a playlist’s subgenre, we automatically know its genre. But the opposite isn’t true , the playlist_genre cannot be used to identify the playlist_subgenre. So playlist_genre and playlist_subgenre should be put into a seperate table that its primary key is the column playlist_subgenre.
df_playlist_name = df_playlist.loc[:,['playlist_id','playlist_name']].drop_duplicates()
df_playlist_name
| playlist_id | playlist_name | |
|---|---|---|
| 0 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix |
| 70 | 37i9dQZF1DWZQaaqNMbbXa | Dance Pop |
| 167 | 37i9dQZF1DX2ENAPP1Tyed | Dance Room |
| 223 | 37i9dQZF1DWSJHnPb1f0X3 | Cardio |
| 272 | 37i9dQZF1DX6pH08wMhkaI | Dance Pop Hits |
| … | … | … |
| 32409 | 0FCHg9zJMNNiOokh3hVcxd | Fresh EDM | Progressive House | Electro House … |
| 32504 | 73uj4YmsC7SJ6SbUMTvf07 | Festival Music 2019 - Warm Up Music (EDM, Big … |
| 32582 | 29jj7pQlDqnWclbHQk21Rq | Underground Party | Hypnotic | Minimal | Acid … |
| 32674 | 4N1ipiKR3xla8UXtE12XBm | Trending EDM by Nik Cooper |
| 32753 | 6jI1gFr6ANFtT8MmTvA2Ux | ♥ EDM LOVE 2020 |
471 rows × 2 columns
df_playlist_subgenre = df_playlist.loc[:,['playlist_id','playlist_subgenre']].drop_duplicates()
df_playlist_subgenre
| playlist_id | playlist_subgenre | |
|---|---|---|
| 0 | 37i9dQZF1DXcZDD7cfEKhW | dance pop |
| 70 | 37i9dQZF1DWZQaaqNMbbXa | dance pop |
| 167 | 37i9dQZF1DX2ENAPP1Tyed | dance pop |
| 223 | 37i9dQZF1DWSJHnPb1f0X3 | dance pop |
| 272 | 37i9dQZF1DX6pH08wMhkaI | dance pop |
| … | … | … |
| 32409 | 0FCHg9zJMNNiOokh3hVcxd | progressive electro house |
| 32504 | 73uj4YmsC7SJ6SbUMTvf07 | progressive electro house |
| 32582 | 29jj7pQlDqnWclbHQk21Rq | progressive electro house |
| 32674 | 4N1ipiKR3xla8UXtE12XBm | progressive electro house |
| 32753 | 6jI1gFr6ANFtT8MmTvA2Ux | progressive electro house |
480 rows × 2 columns
df_subgenre_genre = df_playlist.iloc[:,[3,2]].drop_duplicates()
df_subgenre_genre
| playlist_subgenre | playlist_genre | |
|---|---|---|
| 0 | dance pop | pop |
| 1298 | post-teen pop | pop |
| 2427 | electropop | pop |
| 3835 | indie poptimism | pop |
| 5507 | hip hop | rap |
| 6829 | southern hip hop | rap |
| 8504 | gangster rap | rap |
| 9962 | trap | rap |
| 11253 | album rock | rock |
| 12318 | classic rock | rock |
| 13614 | permanent wave | rock |
| 14719 | hard rock | rock |
| 16204 | tropical | latin |
| 17492 | latin pop | latin |
| 18754 | reggaeton | latin |
| 19703 | latin hip hop | latin |
| 21359 | urban contemporary | r&b |
| 22764 | hip pop | r&b |
| 24020 | new jack swing | r&b |
| 25153 | neo soul | r&b |
| 26790 | electro house | edm |
| 28301 | big room | edm |
| 29507 | pop edm | edm |
| 31024 | progressive electro house | edm |
Finally, we have a series of tables for each entity.
We have to create tables to connect tracks with albums as well as playlists.
df_track_album = df.iloc[:,[0,4]].drop_duplicates()
df_track_album
| track_id | track_album_id | |
|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | 2oCs0DGTsRO98Gh5ZSl2Cx |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | 63rPSO264uRjW1X5E6cWv6 |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | 1HoSmj2eLcsrR0vE9gThr4 |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | 1nqYsOef1yKKuGOVchbsk6 |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | 7m7vv9wlQ4i0LFuJiE2zsQ |
| … | … | … |
| 32828 | 7bxnKAamR3snQ1VGLuVfC1 | 2azRoBBWEEEYhqV6sb7JrT |
| 32829 | 5Aevni09Em4575077nkWHz | 6kD6KLxj7s8eCE3ABvAyf5 |
| 32830 | 7ImMqPP3Q1yfUHvsdn7wEo | 0ltWNSY9JgxoIZO4VzuCa6 |
| 32831 | 2m69mhnfQ1Oq6lGtXuYhgX | 1fGrOkHnHJcStl14zNx8Jy |
| 32832 | 29zWqhca3zt5NsckZqDf6c | 0X3mUOm6MhxR7PzxG95rAo |
28356 rows × 2 columns
df_track_playlist = df.loc[:,['track_id','playlist_id']].drop_duplicates()
df_track_playlist
| track_id | playlist_id | |
|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | 37i9dQZF1DXcZDD7cfEKhW |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | 37i9dQZF1DXcZDD7cfEKhW |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | 37i9dQZF1DXcZDD7cfEKhW |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | 37i9dQZF1DXcZDD7cfEKhW |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | 37i9dQZF1DXcZDD7cfEKhW |
| … | … | … |
| 32828 | 7bxnKAamR3snQ1VGLuVfC1 | 6jI1gFr6ANFtT8MmTvA2Ux |
| 32829 | 5Aevni09Em4575077nkWHz | 6jI1gFr6ANFtT8MmTvA2Ux |
| 32830 | 7ImMqPP3Q1yfUHvsdn7wEo | 6jI1gFr6ANFtT8MmTvA2Ux |
| 32831 | 2m69mhnfQ1Oq6lGtXuYhgX | 6jI1gFr6ANFtT8MmTvA2Ux |
| 32832 | 29zWqhca3zt5NsckZqDf6c | 6jI1gFr6ANFtT8MmTvA2Ux |
32251 rows × 2 columns
The structure of normalization is pretty clear. It looks like this:
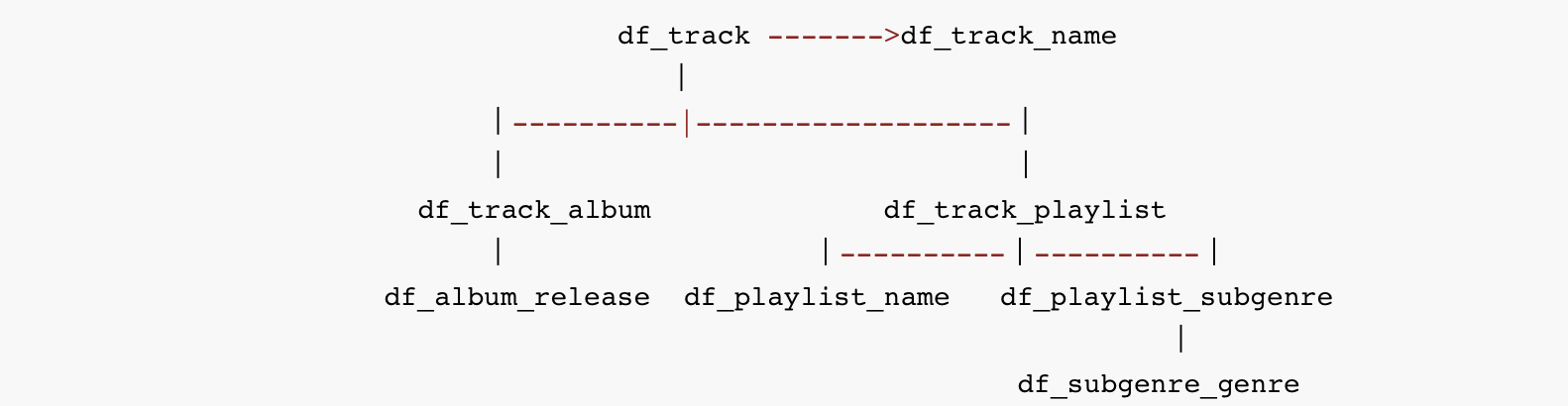
Data Denormalization
After doing data denormalization, we can get a dataset nearly same as the original one.
(
df_track.
merge(df_track_name).
merge(df_track_album).
merge(df_album_name).
merge(df_album_release).
merge(df_track_playlist).
merge(df_playlist_name).
merge(df_playlist_subgenre).
merge(df_subgenre_genre)
)
| track_id | track_artist | track_popularity | danceability | energy | key | loudness | mode | speechiness | acousticness | … | tempo | duration_ms | track_name | track_album_id | track_album_name | track_album_release_date | playlist_id | playlist_name | playlist_subgenre | playlist_genre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6f807x0ima9a1j3VPbc7VN | Ed Sheeran | 66 | 0.748 | 0.916 | 6 | -2.634 | 1 | 0.0583 | 0.1020 | … | 122.036 | 194754 | I Don’t Care (with Justin Bieber) - Loud Luxur… | 2oCs0DGTsRO98Gh5ZSl2Cx | I Don’t Care (with Justin Bieber) [Loud Luxury… | 2019-06-14 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix | dance pop | pop |
| 1 | 0r7CVbZTWZgbTCYdfa2P31 | Maroon 5 | 67 | 0.726 | 0.815 | 11 | -4.969 | 1 | 0.0373 | 0.0724 | … | 99.972 | 162600 | Memories - Dillon Francis Remix | 63rPSO264uRjW1X5E6cWv6 | Memories (Dillon Francis Remix) | 2019-12-13 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix | dance pop | pop |
| 2 | 1z1Hg7Vb0AhHDiEmnDE79l | Zara Larsson | 70 | 0.675 | 0.931 | 1 | -3.432 | 0 | 0.0742 | 0.0794 | … | 124.008 | 176616 | All the Time - Don Diablo Remix | 1HoSmj2eLcsrR0vE9gThr4 | All the Time (Don Diablo Remix) | 2019-07-05 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix | dance pop | pop |
| 3 | 75FpbthrwQmzHlBJLuGdC7 | The Chainsmokers | 60 | 0.718 | 0.930 | 7 | -3.778 | 1 | 0.1020 | 0.0287 | … | 121.956 | 169093 | Call You Mine - Keanu Silva Remix | 1nqYsOef1yKKuGOVchbsk6 | Call You Mine - The Remixes | 2019-07-19 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix | dance pop | pop |
| 4 | 1e8PAfcKUYoKkxPhrHqw4x | Lewis Capaldi | 69 | 0.650 | 0.833 | 1 | -4.672 | 1 | 0.0359 | 0.0803 | … | 123.976 | 189052 | Someone You Loved - Future Humans Remix | 7m7vv9wlQ4i0LFuJiE2zsQ | Someone You Loved (Future Humans Remix) | 2019-03-05 | 37i9dQZF1DXcZDD7cfEKhW | Pop Remix | dance pop | pop |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 32943 | 4XEQqy7GlKVKKoC34yE0RU | Malian Musicians | 37 | 0.285 | 0.419 | 9 | -13.454 | 0 | 0.0427 | 0.6970 | … | 120.026 | 319293 | Spoons | 40ncJvz2FvF1Z4EvpE3vU9 | Mali Music | 2002-04-15 | 37i9dQZF1DWVyizF9BJ61m | Afro Psychedelica | classic rock | rock |
| 32944 | 1D3NaA8JL6QrKoYNj4BKN0 | Jamshied Sharifi | 0 | 0.679 | 0.474 | 2 | -15.384 | 0 | 0.0311 | 0.4700 | … | 130.019 | 173000 | Hyena | 63Llqn2jgqa0yKscAVGsuK | Footsteps In Africa - The Soundtrack | 2009-09-18 | 37i9dQZF1DWVyizF9BJ61m | Afro Psychedelica | classic rock | rock |
| 32945 | 4ttKTDA9f5i2dAPSOqTRtB | Vieux Farka Touré | 0 | 0.441 | 0.611 | 10 | -5.610 | 1 | 0.0314 | 0.7440 | … | 92.581 | 303227 | Fafa | 6ulGA7Fh0lxzmlG1r6OOwR | Fondo | 2009-05-26 | 37i9dQZF1DWVyizF9BJ61m | Afro Psychedelica | classic rock | rock |
| 32946 | 2vbRZMSsenMBhpF6am4uRc | Itadi | 31 | 0.629 | 0.734 | 0 | -10.326 | 1 | 0.0467 | 0.2130 | … | 88.093 | 370469 | Watch Your Life | 0FPxNka2LFpFgHTT5zCtRj | Itadi | 2013-05-03 | 37i9dQZF1DWVyizF9BJ61m | Afro Psychedelica | classic rock | rock |
| 32947 | 0Etl0p4Z6doS0xFxqdhrOn | Tinariwen | 46 | 0.494 | 0.661 | 10 | -7.540 | 0 | 0.0470 | 0.4860 | … | 89.659 | 260253 | Toumast Tincha | 3mBVW4xMIksTDGtYbjrpee | Emmaar | 2014-02-10 | 37i9dQZF1DWVyizF9BJ61m | Afro Psychedelica | classic rock | rock |
32948 rows × 23 columns
Create SQLite Schema and Store tables
import sqlite3
conn = sqlite3.connect('hw4.db')
import pandas as pd
df = pd.read_csv('spotify_songs.csv')
df.to_sql('spotify_songs', conn, if_exists = 'replace', index=False)
df_track.to_sql('df_track',
conn,
if_exists='replace',
index = False)
df_track_name.to_sql('df_track_name', conn, if_exists='replace', index = False)
df_track_album.to_sql('df_track_album', conn, if_exists='replace', index = False)
df_album_name.to_sql('df_album_name', conn, if_exists='replace', index = False)
df_album_release.to_sql('df_album_release', conn, if_exists='replace', index = False)
df_track_playlist.to_sql('df_track_playlist', conn, if_exists='replace', index = False)
df_playlist_name.to_sql('df_playlist_name', conn, if_exists='replace', index = False)
df_playlist_subgenre.to_sql('df_playlist_subgenre', conn, if_exists='replace', index = False)
df_subgenre_genre.to_sql('df_subgenre_genre', conn, if_exists='replace', index = False)
c = conn.cursor()
c.execute("SELECT * FROM sqlite_master WHERE type='table'")
c.fetchall()
These are all the tables we have in the database “hw4.db”:
[('table',
'spotify_songs',
'spotify_songs',
2,
'CREATE TABLE "spotify_songs" (\n"track_id" TEXT,\n "track_name" TEXT,\n "track_artist" TEXT,\n "track_popularity" INTEGER,\n "track_album_id" TEXT,\n "track_album_name" TEXT,\n "track_album_release_date" TEXT,\n "playlist_name" TEXT,\n "playlist_id" TEXT,\n "playlist_genre" TEXT,\n "playlist_subgenre" TEXT,\n "danceability" REAL,\n "energy" REAL,\n "key" INTEGER,\n "loudness" REAL,\n "mode" INTEGER,\n "speechiness" REAL,\n "acousticness" REAL,\n "instrumentalness" REAL,\n "liveness" REAL,\n "valence" REAL,\n "tempo" REAL,\n "duration_ms" INTEGER\n)'),
('table',
'df_track',
'df_track',
2214,
'CREATE TABLE "df_track" (\n"track_id" TEXT,\n "track_artist" TEXT,\n "track_popularity" INTEGER,\n "danceability" REAL,\n "energy" REAL,\n "key" INTEGER,\n "loudness" REAL,\n "mode" INTEGER,\n "speechiness" REAL,\n "acousticness" REAL,\n "instrumentalness" REAL,\n "liveness" REAL,\n "valence" REAL,\n "tempo" REAL,\n "duration_ms" INTEGER\n)'),
('table',
'df_track_name',
'df_track_name',
3116,
'CREATE TABLE "df_track_name" (\n"track_id" TEXT,\n "track_name" TEXT\n)'),
('table',
'df_track_album',
'df_track_album',
3450,
'CREATE TABLE "df_track_album" (\n"track_id" TEXT,\n "track_album_id" TEXT\n)'),
('table',
'df_album_name',
'df_album_name',
3817,
'CREATE TABLE "df_album_name" (\n"track_album_id" TEXT,\n "track_album_name" TEXT\n)'),
('table',
'df_album_release',
'df_album_release',
4083,
'CREATE TABLE "df_album_release" (\n"track_album_id" TEXT,\n "track_album_release_date" TEXT\n)'),
('table',
'df_track_playlist',
'df_track_playlist',
4306,
'CREATE TABLE "df_track_playlist" (\n"track_id" TEXT,\n "playlist_id" TEXT\n)'),
('table',
'df_playlist_name',
'df_playlist_name',
4724,
'CREATE TABLE "df_playlist_name" (\n"playlist_id" TEXT,\n "playlist_name" TEXT\n)'),
('table',
'df_playlist_subgenre',
'df_playlist_subgenre',
4732,
'CREATE TABLE "df_playlist_subgenre" (\n"playlist_id" TEXT,\n "playlist_subgenre" TEXT\n)'),
('table',
'df_subgenre_genre',
'df_subgenre_genre',
4738,
'CREATE TABLE "df_subgenre_genre" (\n"playlist_subgenre" TEXT,\n "playlist_genre" TEXT\n)')]
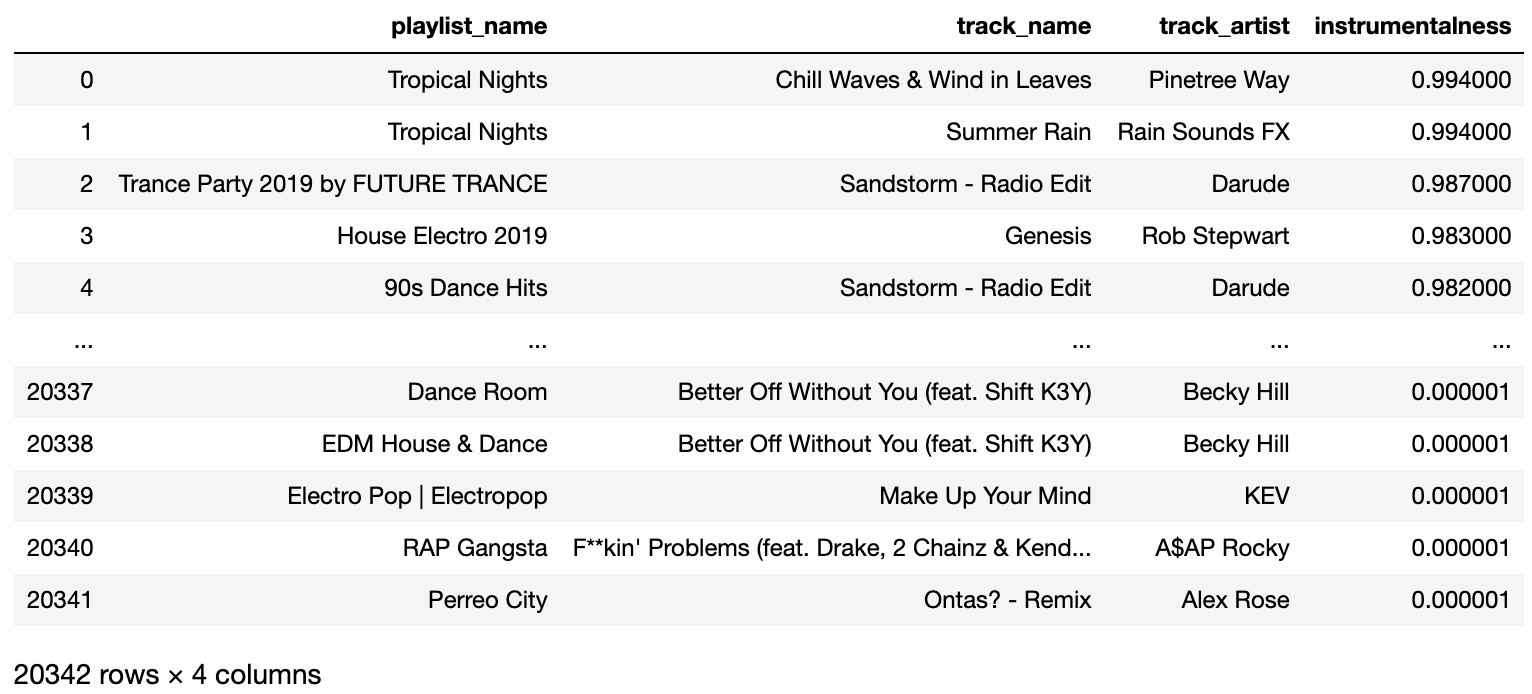
SQL query for playlists that contain instrumentals
query = '''
SELECT playlist_name, df_track_name.track_name, df_track.track_artist, df_track.instrumentalness
FROM df_track
LEFT JOIN
df_track_name
ON df_track.track_id = df_track_name.track_id
LEFT JOIN
df_track_playlist
ON df_track.track_id = df_track_playlist.track_id
LEFT JOIN
df_playlist_name
ON df_playlist_name.playlist_id = df_track_playlist.playlist_id
WHERE df_track.instrumentalness > 0 -- a query contains instrumentals when its instrumentalness is greater than zero
ORDER BY df_track.instrumentalness DESC
'''
pd.read_sql(query, conn)